优化数据实现机器学习高吞吐量 数据处理与存储服务的支持策略
在机器学习(ML)应用中,实现高数据吞吐量是提升模型训练效率、加速实验迭代和确保系统可扩展性的关键。高吞吐量意味着系统能够在单位时间内处理大量数据,从而减少瓶颈,充分利用计算资源。要达成这一目标,需在数据处理和存储服务两个层面进行系统性优化。以下是具体的策略与实践。
一、数据处理优化:实现高效的数据流水线
数据处理是机器学习工作流的第一步,其效率直接影响后续模型训练的吞吐量。
- 并行化与分布式处理:
- 框架选择:利用Apache Spark、Dask或Ray等分布式计算框架,将数据加载、转换和特征工程任务分布到多个节点上并行执行。
- 向量化操作:在数据预处理中,使用NumPy、Pandas(结合Numba)或GPU加速库(如CuDF、RAPIDS)进行向量化计算,避免低效的循环。
- 流水线并行:将数据读取、解码、增强、批处理等步骤组织成异步流水线,使数据预处理与模型训练/推理重叠进行,避免GPU/TPU等待数据。TensorFlow的
tf.dataAPI和PyTorch的DataLoader(配合多进程)是优秀工具。
- 数据格式与序列化优化:
- 采用列式存储格式:对于结构化数据,使用Parquet、ORC或Apache Arrow等格式。它们支持高效的列式扫描、压缩和谓词下推(过滤数据在读取时完成),大幅减少I/O。
- 使用高效序列化:对于非结构化数据(如图像、文本序列),考虑使用TFRecord(TensorFlow)、LMDB或WebDataset等格式,它们通常具有更快的读取速度和更好的随机访问支持。
- 压缩:应用Snappy、Zstandard或LZ4等快速压缩算法,在节省存储空间的最小化解压开销。
- 智能数据加载与缓存:
- 预取与缓存:在数据加载器中设置合理的预取缓冲区大小,提前将下一批数据加载到内存。对于频繁访问的小型数据集或特征,可将其完全缓存在内存或高速缓存(如Redis)中。
- 选择性加载:仅加载训练所需的特征列和数据分区,避免不必要的I/O。
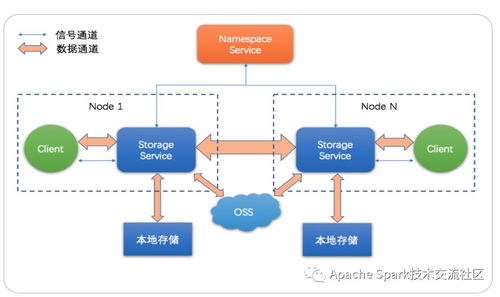
二、存储服务优化:构建高带宽、低延迟的数据基础
数据存储是数据管道的源头,其性能至关重要。
- 存储架构选择:
- 对象存储与文件系统的结合:对于海量原始数据,使用高扩展性、成本效益好的对象存储(如AWS S3、Google Cloud Storage、阿里云OSS)。为需要高IOPS和低延迟的中间数据或热数据,配置高性能并行文件系统(如Lustre、GPFS)或SSB支持的云盘。
- 数据分层:实施热、温、冷数据分层策略。热数据(高频访问)放在高性能存储;温、冷数据移至成本更低的存储层,并通过策略自动迁移。
- 网络与I/O优化:
- 高带宽网络:确保存储集群与计算集群之间具备高带宽、低延迟的网络连接(如云环境中的增强型网络、InfiniBand)。
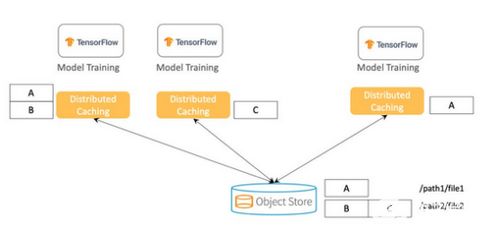
- 客户端缓存与本地SSD:在计算节点上使用本地NVMe SSD作为缓存层,存储当前任务频繁访问的数据块,极大减少远程读取延迟。Alluxio或TensorFlow的
tf.data服务可以协助实现分布式缓存。
- 并发读取:设计数据存储布局(如合理分片/分区),使多个计算节点或进程能够并发读取不同部分的数据,聚合I/O带宽。
- 元数据管理与索引:
- 高效的元数据服务:对于文件系统,确保元数据服务器(MDS)性能可扩展,避免因文件列举、状态检查等操作成为瓶颈。
- 数据索引:对于需要复杂查询的数据集,使用数据库(如PostgreSQL、云原生数据仓库)或索引文件来快速定位所需数据子集,避免全表扫描。
三、端到端协同与监控
优化需要全局视角和持续迭代。
- 剖析与瓶颈识别:使用性能剖析工具(如PyTorch Profiler、TensorFlow Profiler、系统级工具如
iostat、nvidia-smi)持续监控数据流水线,识别瓶颈究竟在CPU、I/O、网络还是反序列化环节。 - 数据版本与管道即代码:使用DVC、MLflow或Pachyderm等工具管理数据版本和可复现的数据处理管道,确保优化后的流程能够稳定、一致地运行。
- 自动化与弹性:在云环境中,利用自动扩缩容功能,根据任务队列动态调整计算和存储资源,为数据处理任务匹配适量的资源。
###
实现机器学习的高数据吞吐量是一个涉及数据、计算和存储的系统工程。核心思想在于:通过并行化与流水线化最大化处理效率,通过选择合适的数据格式和存储架构最小化I/O与延迟,并通过持续的监控与迭代使整个系统保持平衡与高效。将上述数据处理与存储服务的优化策略有机结合,能够为大规模机器学习训练和推理提供坚实、高效的数据支撑,从而释放硬件算力的全部潜能,加速AI应用的开发与部署。
如若转载,请注明出处:http://www.668a2.com/product/61.html
更新时间:2026-06-19 06:19:28