优维可观测轴心产品大观 HyperInsight超融合持续可观测解决方案的数据处理与存储支持服务探析
在数字化浪潮席卷全球的今天,企业的IT系统日益复杂,对系统稳定性、性能与安全性的要求也达到了前所未有的高度。优维科技(UWinTech)推出的HyperInsight超融合持续可观测解决方案,正是响应这一时代需求的产物,它旨在为企业提供从数据采集、处理、存储到智能分析的端到端可观测能力。其中,强大、高效且可靠的数据处理与存储支持服务,构成了该解决方案的核心引擎,是其实现“持续可观测”愿景的坚实基石。本文将深入探讨HyperInsight在这一关键环节的技术架构与服务优势。
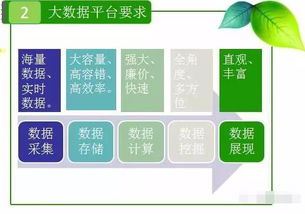
一、 数据处理:实时、高效、智能的流水线
HyperInsight的数据处理服务,构建了一条高度自动化、智能化的数据流水线,负责对接入的海量、多源、异构的可观测数据(包括指标、日志、追踪、事件等)进行实时处理。
- 统一接入与标准化:解决方案支持通过Agent、SDK、API等多种方式,无缝接入来自基础设施、应用、微服务、网络、用户体验等各个层面的数据。面对不同格式和协议的数据(如Prometheus指标、结构化/非结构化日志、OpenTelemetry追踪数据等),数据处理层首先进行规范化与标准化,将其转化为统一的内部数据模型,为后续的关联分析与统一查询打下基础。
- 实时流处理:基于高性能的流处理引擎,HyperInsight能够对数据进行毫秒级的实时处理。这不仅包括基础的清洗、过滤、富化(如添加业务标签、关联上下文信息),更关键的是能够实时执行预定义的规则与算法,进行异常检测、模式识别和事件关联。例如,能够即时发现指标突刺、错误率飙升或调用链异常,并生成告警事件。
- 智能降噪与聚合:为了避免数据洪流淹没真正有价值的信息,数据处理层集成了智能算法,能够自动对相似事件进行聚合,对告警进行根因分析与降噪,将成千上万的原始告警收敛为少数几个核心问题,极大提升了运维效率。
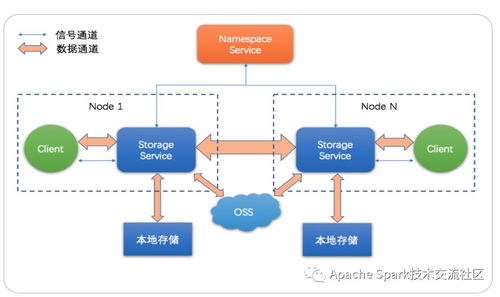
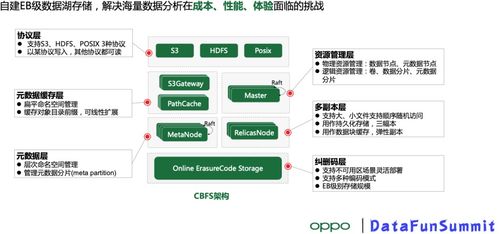
二、 数据存储:弹性、融合、高性能的“数据湖仓”
处理后的数据需要被高效、持久地存储,并支持灵活、快速的查询分析。HyperInsight的存储支持服务采用了一种融合“数据湖”与“数据仓库”优势的先进架构。
- 分层存储与成本优化:根据数据的访问频率和重要性,系统自动实施分层存储策略。高频访问的热数据(如最近几小时/几天的明细数据)存储在基于SSD的高性能存储引擎中,确保仪表盘、实时排查的极致速度。温数据和冷数据则自动沉降到成本更优的对象存储或分布式文件系统中,同时保证其可查询性。这种设计在保证性能的显著降低了长期的存储总成本。
- 多模融合存储引擎:HyperInsight并未为指标、日志、追踪分别建立孤立的存储,而是通过创新的索引与存储格式,在一个融合的存储引擎中高效地组织这些不同类型的数据。这使得“Metrics、Logs、Traces”的关联查询(如“查看这个慢接口对应的错误日志和上下游调用链”)变得异常高效和自然,打破了传统监控工具中的数据孤岛,真正实现了全栈可观测数据的贯通。
- 无限扩展与高可用:存储架构采用分布式设计,支持水平无限扩展。无论是数据吞吐量还是存储容量,都可以通过增加节点线性提升,从容应对业务快速增长带来的数据膨胀。通过多副本、跨可用区部署等机制,保障了数据的高可用性与持久性,满足企业级可靠性要求。
- 开放与生态兼容:在存储接口上,HyperInsight提供了对PromQL、SQL等多种查询语言的支持,并兼容主流开源生态的协议,降低了用户的学习与迁移成本,保护了现有投资。
三、 服务价值:驱动智能运维与业务洞察
强大的数据处理与存储支持服务,最终服务于更高层的价值目标:
- 保障系统稳定性:通过实时处理与智能分析,快速定位故障根因,实现从“救火”到“预防”的运维模式转变。
- 提升用户体验:关联业务指标与性能数据,精准分析用户体验瓶颈,驱动产品优化。
- 优化资源成本:智能的数据分层与高效的存储格式,直接降低了海量可观测数据的存储与计算开销。
- 赋能业务决策:沉淀的系统运行数据与业务数据相结合,为容量规划、架构演进和业务决策提供数据驱动的洞察。
优维HyperInsight超融合持续可观测解决方案,以其在数据处理与存储支持服务方面的深厚技术功底,构建了一个既能应对海量数据冲击,又能提供深度智能分析的坚实数据基座。它不仅是一个强大的运维工具,更是企业数字化转型中,将系统运行数据转化为核心竞争力的关键引擎。通过将数据的“管、存、用”融为一体,HyperInsight正助力越来越多的企业实现系统可观测性的全面升级,从容驾驭云原生时代的复杂性与不确定性。
如若转载,请注明出处:http://www.668a2.com/product/58.html
更新时间:2026-06-19 16:19:01