亿级数据湖统一存储技术实践 构建高效数据处理与存储支持服务
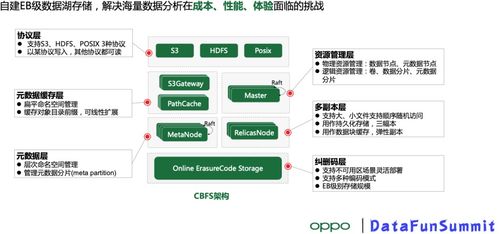
在当今数据驱动的时代,企业面临着数据规模爆炸式增长、数据类型日益多样化、数据处理需求实时化的多重挑战。构建一个能够容纳并高效管理亿级乃至更大量级数据的统一存储平台——数据湖,已成为众多企业的核心战略。本文将探讨亿级数据湖的统一存储技术实践,并重点阐述其如何为上层的数据处理与分析提供强大的存储支持服务。
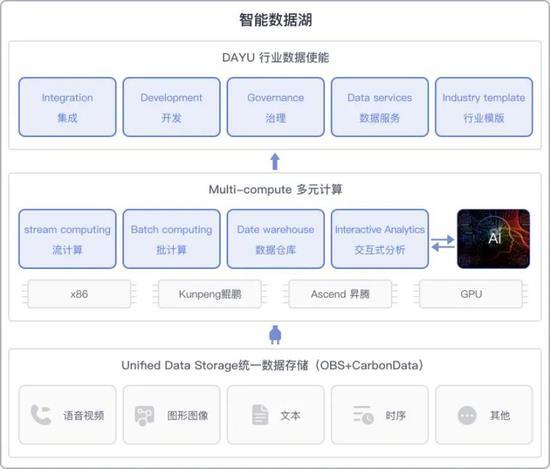
一、 数据湖统一存储的核心理念与架构
传统的数据仓库模式因其严格的结构化要求和模式预定义,难以应对海量半结构化、非结构化数据以及快速变化的业务需求。数据湖应运而生,其核心理念是“先存储,后定义”,即以原始格式(如Parquet、ORC、Avro、JSON、文本、图像、音视频等)集中存储企业内所有类型的数据,而不预先施加模式限制。
一个典型的亿级数据湖统一存储架构通常包含以下层次:
- 存储层:基于可扩展的对象存储(如AWS S3、阿里云OSS、华为云OBS)或分布式文件系统(如HDFS)构建,提供海量、低成本、高可靠的底层存储能力。这是数据湖的“湖盆”。
- 数据组织与元数据管理层:这是数据湖的“大脑”。通过统一的元数据服务(如Hive Metastore、AWS Glue Data Catalog、Apache Iceberg/Hudi/Deltalake的元数据表),对存储在底层的大量文件进行编目、定义表结构、记录数据版本、分区信息及访问权限,使原始数据变得可发现、可管理、可治理。
- 计算与处理层:各类计算引擎(如Spark、Flink、Presto/Trino、Hive)通过统一的连接器或接口,直接访问存储层的数据,并利用元数据层的信息进行高效的查询和分析。存储与计算分离是此架构的关键特征。
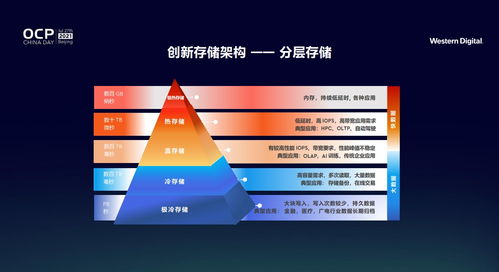
- 安全、治理与生命周期管理层:贯穿始终,提供统一的身份认证、权限控制、数据加密、数据血缘、质量监控及冷热数据分层存储策略,确保数据湖的安全、合规与成本可控。
二、 关键技术实践:为数据处理提供坚实支持
1. 采用高性能列式存储格式
对于大规模分析型负载,将原始数据转换为Parquet或ORC等列式存储格式至关重要。这类格式具有极高的压缩比,能显著减少I/O和存储成本;其列式特性允许查询引擎仅读取所需列,大幅提升扫描效率,直接加速了上层的Spark SQL、Presto等查询性能。
2. 实施精细化的数据分区与分桶策略
对海量数据按时间(如天、小时)、地域、业务维度进行分区,是提升查询性能最有效的手段之一。分区能将全表扫描转化为部分分区扫描。结合分桶(Bucketing)技术,可以进一步在分区内将数据散列到固定数量的文件中,优化JOIN操作和数据采样。合理的分区策略是元数据管理的重要部分,直接服务于查询优化。
3. 拥抱开源数据表格式(Table Format)
使用Apache Iceberg、Apache Hudi或Delta Lake等表格式,是构建现代数据湖的统一存储实践的核心。它们通过在元数据层提供ACID事务、时间旅行(快照查询)、增量读取、模式演进、并发控制等高级特性,将简单的文件集合提升为“数据表”。这极大地简化了数据处理流水线(如流批一体、CDC入湖)的构建,保证了数据的一致性和可靠性,为上层的计算引擎提供了稳定、高效的接口。
4. 构建统一的元数据与数据目录服务
一个集中、统一的元数据目录是所有数据处理任务发现和理解数据的基础。它应该支持自动化的元数据发现与采集、业务术语标注、数据血缘追踪和数据质量规则定义。强大的数据目录使得数据分析师和数据科学家能够快速找到所需数据,理解其含义和来源,这是数据湖发挥价值的前提。
5. 实现存储与计算资源的弹性解耦与优化
利用云上对象存储的无限扩展性和按需付费特性,存储层可以独立于计算集群进行伸缩。计算资源(如Spark集群)可以根据处理任务的需要动态启停和扩缩容,无需为存储绑定昂贵的固定硬件。通过智能缓存(如Alluxio)将热数据缓存在计算节点附近,可以弥补对象存储可能存在的延迟短板,为交互式查询提供加速支持。
三、 存储支持服务的具体体现
统一的数据湖存储平台,为上层的数据处理提供了全方位的“支持服务”:
- 对批量处理的支撑:为大规模的ETL/ELT作业提供高吞吐量的数据读取和写入能力。优化的存储格式和分区策略直接决定了批处理作业的运行效率与成本。
- 对流式处理的支撑:通过与流计算引擎(如Flink、Spark Streaming)及Kafka等消息队列的集成,支持实时数据持续入湖。Iceberg等表格式的增量读取和流式写入能力,是实现流批一体架构的关键存储基础。
- 对交互式分析的支撑:为Presto/Trino、Impala等即席查询引擎提供低延迟的数据访问路径。列式存储、分区修剪、统计信息(由元数据管理)以及可能的缓存层,共同保障了亚秒级到秒级的查询响应。
- 对数据科学与AI的支撑:以原始或预处理后的格式存储非结构化数据(图像、日志),并通过标准接口(如S3协议、HDFS API)提供给TensorFlow、PyTorch等框架进行模型训练,避免了数据在不同系统间迁移的麻烦。
- 对数据治理与安全的支撑:统一的权限模型(如基于AWS IAM或Ranger的细粒度访问控制)、审计日志和加密机制,确保所有数据处理操作都在受控的安全环境下进行。
四、 实践挑战与展望
实践中,构建和管理亿级数据湖仍需应对诸多挑战:小文件问题导致的性能下降、跨地域数据访问的延迟、不断攀升的存储成本控制、以及日益严格的数据合规要求。未来的技术实践将更侧重于:
- 自动化与智能化:利用AI进行数据自动分类、优化建议(如自动分区、压缩)、异常检测和成本管理。
- 湖仓一体演进:在数据湖的灵活性与数据仓库的性能与治理之间取得更好平衡,提供统一的数据体验。
- 跨云与混合云部署:满足企业多云战略,实现数据与计算在异构环境下的无缝流动与管理。
****
亿级数据湖的统一存储实践,绝非仅仅是堆积海量存储空间。它是一个以统一、高效、安全的存储层为核心,通过先进的元数据管理、表格式和存储优化技术,向上层多样化的数据处理范式提供标准化、高性能支持服务的系统性工程。成功的实践将使数据湖真正成为企业汇聚数据资产、挖掘数据价值的坚实基石,赋能业务创新与智能决策。
如若转载,请注明出处:http://www.668a2.com/product/65.html
更新时间:2026-06-19 19:39:53